Some Perspective
Back in 2019 I pushed out a quick snippet talking about why software seems to always be broken. Well if anything has proven since that time to have not corrected itself, this would most certainly be it. But why? We have so many people focused in this field currently that its hard to imagine that we haven't gotten better at producing higher quality software at this point but here we are. I put together a quick sampling below of things that come to my mind pretty quickly when I ask myself what has happened in the past 50+ years.
Early Programmers were Amazing
Everyone should read some of the early books produced by names such as Brian Kerrighan and Dennis Ritchie, Thomas Cormen et al, W. Stevens, and my personal hero, John McCarthy. These people were truly world changing individuals that really understood how computers functioned at the lowest levels and how to write code that not only worked, but worked in a very optimized manner. Unfortunately, I would venture to guess that if I walked into a CS101 class today and asked all the students if they read books by any of these people or even knew who they were that outside of possibly K&R, they would have no idea.
How can you know know where you are going, if you don't know where you originated from? The concepts that these individuals, I mean giants, present are still true today, and yet many people don't know very much about them, or even more painful for me personally, want to know anything about them.
Forgotten, Lost, and Ignored Wisdom
I recently started reading the Lisp 1.5 Programmers Manual and was so overtaken by the knowledge that McCarthy was trying to convey. Understanding what his vision was at the time and how the Lisp Interpreter is designed. For a programmer, its like looking at Mona Lisa as you can see the true beauty in what he was creating. Unfortunately now I see no beauty in the same way when I look at a significant amount of source code. Not so say there isn't still a lot of really good code in existence, but I do see a lot of sloppy copy/pasted code that in many cases, unfortunately resides in production systems.
I believe we need to understand these concepts that were hacked out years ago in order to properly move forward and improve on what our senseis have taught us. Without a basic understanding and the leveraging of their guidance we are destined to continually reinvent the wheel at best, produce inferior software in many cases, or as Jonathan Blow mentioned in the talk I highlighted in my prior post, completely lose that skill to time as has occurred in the past.
Features Verses Quality
If ignorance of software engineering principals wasn't enough, there is now a growing pressure to simply get features shipped and out the door. I suspect everyone reading this who has developed commercial software within an organization has some version of this story running through their mind as they read this. Oh yeah, this one time... we had to get this feature out the door due to the business promises that were made. Its OK, if that happened to you.. know that you aren't alone.
We Need to Ship Next Week, We Made Commitments
This is the classic business comment that frequently rears its ugly head. Was the development team ever consulted before the commitments were made? Was there a change in the requirements during the development cycle? Was there scope creep that appeared in the middle of the cycle? These are all questions that should be asked as to how it reached this point.
It's Only A Small Bug
This is one of my personal favorites... its a small bug, we can live with it in the short term. If you ever hear this red flags should appear immediately. I can guarantee this is going to reappear in some form in the future if a release is cut with "a known small bug", and there will be a major push that will bubble up to the stack as something that needs to be corrected before you can call it a day at some point.
We can Fix that in the Next Release
The immediate follow up to "its a small bug" is this statement. We'll get that next release. Somehow during the initial meetings of every development cycle after this time though, this small bug is always so insignificant that it just seems to fall by the wayside in support of some new feature that just has to get out the door in the upcoming release, because.... hey we made promises.
Summary
Well there you have it, a brief introduction of things that immediately come to my mind as I ponder this subject of software quality today. I suspect that some who read this will consider my thoughts are that of a paranoid crazy open source developer who just doesn't get the modern development process. That CI/CD and agile processes have fixed all of this. I will just answer that with one word, bull. If it were the case, I wouldn't be writing this, and you wouldn't have agreed with one or more of the issues I presented.
Also, I can say that I've had the pleasure to have worked in an organization at one point where code quality was truly put in the fore front. I won't mention the organization but it proved to me that it's possible to write really good high quality code. Believe me, it can be done but everyone involved needs to have that vision. Software quality is really like security at some level, its only as good as its weakest link. We owe it to ourselves and our customers that as the developers we aren't that weakest link. Its how the giants that we hopefully admire and maybe even wanted to emulate when we started down this crazy path of developing software would want us to be.
Until the next blog, don't talk about it...
Time for Change and Cleanup
What a year and a half that it has been been! I can't imagine many other times in my life that everything has been the confused mess that it has for the past 18 months. Its amazing that no matter how much new technology is introduced and scientific proof is given there seems to be a growing number of people in the world that have relieved themselves of any matter of common sense and produce their own logic based in complete non-sense. I really wouldn't care that much normally and would just let Darwin take over to settle the matter but unfortunately innocent people are impacted by the complete idiocy of others this time. I'm not saying that you shouldn't get your concerns and questions answered, but I am saying that Dr. Facebook is probably not the best place to do so. Zuck isn't your friend, I can assure you of that. If there is money to be made from another person's pain, FB is all over it. Ask the number of developers who have either left the company or have turned down interviews with them when they cold called us... just saying.
Current Situation
So what have I been doing over the past 1.5 years or so? Well I've been working on a long term project that has been sitting on the shelf for way too long, spending some time trying to begin to understand Rust, at least enough to be able to make a judgment call on whether it is something I want to deep dive into. Looking very closely at Zig which I definitely want to revisit at some point. Zig looks really interesting, possibly more so than Rust for me. Spending a small amount of time traveling during the gap of goodness as I call it, that was May/June of 2021 and as you can see, making yet another change to my web page.
Why the Change?
Don't get me wrong, I really liked the layout and design of my page prior to this one. It was very professional looking IMHO and just eye catching. I have several reasons really for the change.
One is that I spent a lot of time with Haskell working on that page just getting the environment up and running, learning some of the real basics of working with the language. I found it to be a really solid language and also due to its static nature, really picky about things. To Haskell folks this is a positive as with it comes stability of the compiled code and I agree with that. I did find the development environment not something though that was to my liking, not nearly as much as Clojure or Common Lisp. So after I deemed I had given it a good investigation, I thought it was time to select something that would allow me to work in a development environment that fit me personally better and would allow me to increase my knowledge of the language that I choose.
This time it would be more about the understanding the internals of the base language and less about the general "bling" of the site. The CSS in the prior page was actually taken from another person's Hakyll site on GitHub that I went through and attempted to strip down as much as possible. However, the original code they used was actually from a WordPress site so it had gone through several transformations and was just pretty messy at the end of the day. With this new site, I wanted to either clean up that code if I was going to continue to use it, or I was going to go with something completely new that I understood the pieces much better.
The REPL Wins Out
After weighing all of these things I decided to make a change rather than continue to use Hakyll as I found that I wasn't really using Haskell outside of the web site so it didn't make much sense to continue having simply a static website leveraging Haskell for its creation. I did spend a bit of time weighing out if I wanted to try to use Rust for it, but decided against that ultimately. In the end I realized that I just love the REPL.
What is so special about the REPL is a common question that I get from people who have worked in Ruby or in Python (as well as other languages)? Their comments are generally something along the lines of, I can spin up a Python prompt/REPL also, so why is the REPL in a language like Common Lisp different, or better? This is actually something that I may do a deep dive in at some point in the future if I have the time, but I can assure you that there is a difference in the workflow of development between something like Python and Lisp. For now I will leave you with Eric Normand's video What Makes a REPL as a quick introduction that I believe does identify one of the, if not the most important difference.
I could have leveraged Clojure for this but I ended up deciding on Common Lisp, Steel Bank Common Lisp actually in the end. One of the nice features of Lisp is that there exist many flavors of Lisp out there but they will generally all follow the ANSI Standard for Common Lisp. So whether you choose Steel Bank, or Common Lisp, LispWorks, or another Common Lisp, the code will run on all of them.
I picked Steel Bank since it is considered more optimized for speed than Common Lisp and unlike LispWorks is a free option as I won't need to have the support of a pay option at this point.
The actual library that I decided upon is called Coleslaw which seems to work very nicely and does support extensions if I decide to add something that I want later. There are number of sites out there that run Coleslaw so I had access to a few blogs that talked about the configuration and setup procedures.
The Front End
What about the presentation layer? It turns out that Coleslaw does provide some themes by default but I decided to create my own theme using Bootstrap and leveraging some of the themes that exist readily out there for it. I ended up customizing a theme from Bootswatch which wasn't a terrible experience. Once I started to understand their CSS it was relatively simple to get it to look how I wanted it. There are couple of things that I still need to work out, but I think it is pretty nice now. The big thing is that I can maintain this pretty simply at this point.
Summary
Hopefully this read was both interesting and informative. It does feel good to work on this site again and throw out some new content. Something to keep my mind off of the craziness going on in the world at the moment!
Until the next blog, don't talk about it...
My password has been "fido" for years
This is outside of my normal posts, but its been jumping out at me for the past couple of months so I thought I should post something about it. I can't say this any more clearly than if you are using your pets name, STOP! Also don't use your kids name, your spouse's name or anything similar, unless you want to get pwned as that will almost certainly happen at some point if you continue this really terrible practice. Also, be sure to not use any of these passwords as well as they are the most common passwords. If you are currently doing any of these practices, then read on!
Note that this is a huge subject and this read addresses only a very small fraction of the entire story. I'm purposely avoiding a lot of the more complex issues here to avoid clouding up the goal of having people realize that things have changed with regards to passwords and they need to change with them.
Current Situation
The basic levels of encryption that are being used by sites is generally too good to be able to break so the way most passwords are broken (outside of social engineering) is by brute force. Brute force is used by iterating through an entire list of the most common passwords much larger than the above hoping to eventually hit the magic combination that will let them into your account. At the end of the day, if your password is in one of these lists you are certainly susceptible to exploitation and you consider taking action to protect yourself from attack
What is the Remediation?
There are multiple ways to better protect yourself that are currently in widespread use. What we are doing is making the brute force method described above so distasteful for your account that its not possible to break it in a timely manner. If we do that, you are reasonably safe from these types of attacks. Look at the ones outlined below and consider using at least one if not more of them to make your online presence a lot more secure. Here is a really good overview of them if you are interested in digging into them a bit further.
- Short Codes
- Password Databases
- Diceware
- Two Factor Authentication
Short Codes
This has been around for a long time and something that I initially used back in the 90s. Its better than using a dictionary word because its not going to likely be in any password dictionary. The weakness in this is that currently the length that most users go with is not sufficient. Its pretty simple to use though, just think of a long phrase and then take the first letter out of each word in the phrase. A short example would be "My dog is blue and has fleas". In this case (don't actually use this) the password would be "mdibahf". You can then make this more secure by adding capitalization, numbers, and characters in the phrase. So something like "mD1b&Hf" could be your password. This way you just have to remember the phrase and through repetition you will remember the actual password. As I mentioned the recommended length of passwords has increased recently as the computing power has increased. Currently, you really should be looking at 16 or more characters. If you want some examples of these types of passwords, you can try look at this online generator which is quite nice
Password Databases
These are becoming more popular and are really nice to use especially given the recommended length of passwords and wanting to use different passwords on different web sites. I would recommend giving them a try if you have not already done so. Password databases allow you use a single password to access all of your other passwords that are stored either locally or in the cloud so that they can be shared across multiple PCs. Browsers currently have their own brands of these as well if you happen to use Firefox or Chrome. I personally have grown fond of Bitwarden and have used it for some time. It's nice because it supports both web access and access via a smartphone. It is a cloud solution and therefore does allow you to share your passwords across multiple systems easily. It is open source and they have shared their security audit that was performed in in 2020 so you can see how they fared. They do offer a free option that comes without two factor authentication (described a bit later). For anyone that spends significant time on the net, this would be a good option.
Diceware
I've not heard of this prior to reading the article, but it is a very secure method of creating a password. It is a two step process, the first of which is locate a diceware word list. The exact list you decide upon is based upon the number of dice that you plan to role. Here is a five die list. The standard recommendation is five dice. Secondly, you need a locate a dice rolling application online. The site random.org has a nice dice roller application as an example.
The sequence is to do the following:
- Roll x number of dice and record the numbers on each die in order
- Look up the word in the word list with the number represented in the five dice and write it down
- Continue this to obtain a total of six words
- These six words strung together become your new pass phrase
- To assist in memorizing these words create a sentence using them in order
- Continuing to repeat the sentence in your mind will ingrain the sentence and thus your pass phrase.
The sheer number of characters in this pass phrase is what makes it very secure. The length will make it problematic for use in cell phones, but where a keyboard is used, it isn't a difficult operation.
Two Factor Authentication
Finally two factor authorization. You may see this written as 2FA in a lot of places. It can also be called Multi Factor Authentication (MFA). This is adding a secondary authentication method as a requirement once you have passed the first method, usually a username/password combination. It will likely be combined with one of the above listed methods as it is generally always an "add on" method of security used in addition to another method.
Just like password generation technologies, 2FA also has methods that are better than others. Currently the recommendation is to us an application on your device rather than an SMS message which was pretty standard prior. An application like Authy will go a long way to making your life more secure.
The way Authy and similar devices usually work is the following (Assuming the application you are logging into supports Authy).
- Launch Authy
- Add an account, where account is the application that supports
- Authy for 2FA.
- On the application side, when you select that you want 2FA a QR
- code will be presented.
- On the Authy app use the camera to scan the QR code on your monitor
- There will be a username/password that you will be required to add for the account that you want Authy to permit access to.
- You may receive some one time recovery codes that will act as a one time access in the event that you lose the device. Obviously don't store these on the device itself, and never give them to anyone as they are keys to your account.
Once you have 2FA configured for an application, whenever you log into a site and provide your credentials another window will appear asking you to enter a code. Its normally a six digit number. That number can be found within the Authy application for that account just configured. There is a time limit of normally 30 seconds for each code before it changes. The code in the Authy application is entered at the prompt in the application and the login process is completed. Since each application has its own 2FA configuration, this is targeted at the individual application level.
2FA is considered very secure as even if someone somehow does compromise your password, they would not get access to your account unless they could also do the 2FA portion. If you have the ability to use 2FA on any accounts, do so... its one of the most secure simple ways to help ensure the bad guys aren't getting into your stuff.
Summary
Hopefully this quick overview was helpful. There is a lot involved in security, but you need to take it seriously and at some point you need to just jump into the water and start to swim. Maybe reading this can give you the courage to climb up onto the diving board.
Until the next blog, don't talk about it...
Background
Recently I was talking about LLVM with a colleague and the question arose of exactly why the OpenBSD project has an issue with the LLVM license change that occurred a couple of years ago. As I knew only a cursory level reason as to why this occurred, I started to do a little digging into the history and thought it may be of interest. Here is what I came up with.
The Problem
Initially the LLVM project was placed under the NCSA license which is a very open license, much like the license that BSD uses in general. If anyone isn't aware of the BSD license model please take some time and research it separate from this entry if you want to fully understand it. There are many licensing models out there and if you think that the Apache 2, GNU, and ISC are all basically the same, I would suggest doing some reading, as that is where much of the reasoning behind this issue stems from, the nuances of the licenses. OpenBSD has a very clearly stated policy at https://www.openbsd.org/policy.html that outlines what they consider acceptable licenses for code that goes into their project.
I Thought Apache 2 License is Free?
It turns out that the Apache 2 license is free, but the change to it is what is actually in question. The one called out by OpenBSD in particular is that it was possible to change the license without the consent of the people who are listed as contributors in the NCSA license. In addition, what Theo expanded on was the LLVM team’s apparent “IANAL but let’s do it anyway” attitude that seems to indicate they really did not consult someone as to if it was possible to change the license mid stream as they did. The email in this case it isn’t a piece of software that a single person contributed to, and they would be available to provide consent to the license change, this software had been created by a team of contributors. What happens when someone at a time in the future who is listed on the NCSA license calls them out for not getting their permission to perform the license type change?
What will be the fallout?
At the end of the day the OpenBSD project has been forced to stick with the last NCSA licensed version of LLVM. They generally have forked products in the past when this occurs and then will move forward in one of two ways. Either they will create their own version as in the case of LibreSSL and PF, or they will move to another piece of open source software as they did in the case of going from GCC to Clang. Unfortunately now this has bitten them there may be a tendency to write their own, but that is a huge undertaking. I tend to think they will not go the route they have with LibreSSL just due to the scale of building out a compiler toolchain, but one never knows.
This is how it ended for ipfilter. It occurred midstream in a release cycle, with no packet filter in place that could be used at the time. One had to be written from scratch and within the timelines. This is how PF was born. from the CVS commit message:
Remove ipf. Darren Reed has interpreted his (old, new, whichever) license in a way that makes ipf not free according to the rules we established over 5 years ago, at www.openbsd.org/goals.html (and those same basic rules govern the other *BSD projects too). Specifically, Darren says that modified versions are not permitted. But software which OpenBSD uses and redistributes must be free to all (be they people or companies), for any purpose they wish to use it, including modification, use, peeing on, or even integration into baby mulching machines or atomic bombs to be dropped on Australia. Furthermore, we know of a number of companies using ipf with modification like us, who are now in the same situation, and we hope that some of them will work with us to fill this gap that now exists in OpenBSD (temporarily, we hope)
Until the next blog, don't talk about it...
Background
Using LSP (Language Server Protocol) in Emacs brings some of the convenience items present in contemporary IDE's into the Emacs environment that we are all familiar with. Clojure has proven to me to be similar from a development standpoint where it is a relatively small core language with a large number of supporting libraries, similar in many ways to Common LISP.
Having the ability to leverage Emacs with LSP for Clojure development was a really high item on my list of integrations as I saw what clojure-lsp does in a FreeBSD and Debian Linux environment and I wanted to have those capabilities available to me in OpenBSD.
The Problem
The main issue faced when working with OpenBSD is generally its compatibility with various libraries used frequently in the Linux community. Linux users generally are happy when they get their code working in that environment, stopping at that point with porting to other environments. Sometimes FreeBSD will be ported to, but OpenBSD is generally left to fend for itself. Also the OpenBSD environment is not one that is as easy to get working due to its more locked down state.
In the case of clojure-lsp, the default binary found at https://github.com/snoe/clojure-lsp does not include support for OpenBSD for the required sqlite-jdbc driver within the download provided. The sqlite DB is used by LSP for maintaining the details of a project in a quickly accessible location I believe. (Disclaimer I haven't looked at the code to confirm this, it's an assumption) Once Emacs has been configured to leverage clojure-lsp, it tries to create a sqlite DB in a directory ".lsp" at the root of the project. When this is attempted in OpenBSD, the sqlite-jdbc driver isn't contained in the shipped binary, so even though the OS is detected, it doesn't have the proper jdbc binary available to make the connection to the DB, and fails. In Emacs it simply appears at the bottom of the screen as "Connecting" and continues to sit there spinning.
Luckily lsp-clojure by default logs to a file /tmp/lsp.out that contained information regarding this failure, giving us a clue to what is happening. Below is an example of the error.
{:type java.lang.Exception
:message No native library is found for os.name=OpenBSD and
os.arch=x86_64.
path=/org/sqlite/native/OpenBSD/x86_64
:at [org.sqlite.SQLiteJDBCLoader loadSQLiteNativeLibrary
SQLiteJDBCLoader.java 333]}Its pretty apparent from the error that we have a library missing in the shipped binary for
Lets Make this Work
Getting lsp-clojure functional in OpenBSD requires a couple of things to happen.
- Rebuild sqlite-jdbc with support for OpenBSD
- Rebuild clojure-lsp with support for the sqlite-jdbc driver compiled
The next section walks through the process
Prerequisites
- Download the master zip file from the git repo for sqlite-jdbc: https://github.com/xerial/sqlite-jdbc
- Clone the git repo for clojure-lsp: https://github.com/snoe/clojure-lsp
- Ensure the following packages are installed for compiling
- bash
- gmake
- lein
- maven
- Emacs has been properly configured for LSP and lsp-clojure as noted on their respective web-sites.
Compiling an OpenBSD version of the sqlite-jdbc driver
- Unzip sqlite-jdbc-master.zip
- Edit the Makefile so it only compiles native
- modify the line as shown in Makefile
#native-all: native win32 win64 mac64 linux32 linux64 linux-arm
#linux-armv7 linux-arm64 linux-android-arm linux-ppc64 alpine-linux64
native-all: native- Using gmake compile sqlite-jdbc
- The native compile will only build the host OS version
- It was not possible to get the other OS versions to build easily, so they were ignored.
% gmakeOnce its built, we need to have this installed in the local .m2 repository of the user's home directory. This is needed as when we build clojure-lsp we need to have this driver available. We use maven to perform the installation locally. This will run through some tests as part of the install process and at the end of the process an INFO line shows where it was installed.
$ mvn install
[INFO] Scanning for projects...
[INFO]
[INFO] -----------------------< org.xerial:sqlite-jdbc >-----------------------
[INFO] Building SQLite JDBC 3.31.2-SNAPSHOT
[INFO] --------------------------------[ jar ]---------------------------------
[INFO] --- maven-install-plugin:2.4:install (default-install) @ sqlite-jdbc ---
[INFO] Installing
/home/roger/Downloads/sqlite-jdbc-master/target/
sqlite-jdbc-3.31.2-SNAPSHOT.jar
to /home/roger/.m2/repository/org/
xerial/sqlite-jdbc/3.31.2-SNAPSHOT/sqlite-jdbc-3.31.2-SNAPSHOT.jar
[INFO] Installing /home/roger/Downloads/sqlite-jdbc-master/pom.xml to
/home/roger/.m2/repository/org/xerial/sqlite-jdbc/3.31.2-SNAPSHOT/
sqlite-jdbc-3.31.2-SNAPSHOT.pom
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 11.980 s
[INFO] Finished at: 2020-06-07T15:49:36-04:00
[INFO] ------------------------------------------------------------------------
Now that the driver is ready and installed, go to the git cloned directory for clojure-lsp and make the following changes to the deps.edn file. Make sure that the versions being built match your individual versions. By default Leiningen will look to the .m2 directory of the user running the build first, if it doesn't find the file there, it the searches these: clojars.org and Maven Central. By installing the library to the local cache, it will not go out to look for it. If it does try to look outside of the local repo, obviously this will fail.
;;org.xerial/sqlite-jdbc {:mvn/version "3.21.0.1"}
org.xerial/sqlite-jdbc {:mvn/version "3.31.2-SNAPSHOT"}Now its time to build a new version of clojure-lsp with support for OpenBSD. By default lein does not allow SNAPSHOTS in release build libraries as dependencies, it will trigger an error. If a SNAPSHOT was used as above, its necessary to tell Leiningen this is OK before we build clojure-lsp.
% cd <CLOJURE_LSP_DIR>
% LEIN_SNAPSHOTS_IN_RELEASE=1
% export LEIN_SNAPSHOTS_IN_RELEASE
% <PATH TO LEIN> bin
WARNING: You have $CLASSPATH set, probably by accident.
It is strongly recommended to unset this before proceeding.
WARNING: seqable? already refers to: #'clojure.core/seqable? in
namespace:
clojure.core.incubator, being replaced by: #'clojure.core
.incubator/seqable?
WARNING: seqable? already refers to: #'clojure.core/seqable? in
namespace:
clostache.parser, being replaced by: #'clojure.core.incub
ator/seqable?
Compiling 1 source files to /home/roger/src/clojure/clojure-lsp/target/classes
Compiling clojure-lsp.clojure-core
Compiling clojure-lsp.crawler
Compiling clojure-lsp.db
Compiling clojure-lsp.handlers
Compiling clojure-lsp.interop
Compiling clojure-lsp.main
Compiling clojure-lsp.parser
Compiling clojure-lsp.refactor.edit
Compiling clojure-lsp.refactor.transform
Compiling clojure-lsp.shared
Created /home/roger/src/clojure/clojure-lsp/target/
clojure-lsp-release-20200514T134144.jar
Created /home/roger/src/clojure/clojure-lsp/target/
clojure-lsp-release-20200514T134144-standalone.jar
Creating standalone executable: /home/roger/src/clojure/clojure-lsp/
target/clojure-lsp
Re-aligning zip offsetsCopy the clojure-lsp file created as "standalone executable" to a location available in your PATH within your .emacs.
Open Emacs and load a clojure file from a project into Emacs.
When this is performed, it should launch the lsp process and you will see some message indicating STATUS:starting at the bottom of the Emacs window. After some time.. depending upon the processor, maybe 20-30 seconds, that should change to:
LSP :: clojure-lsp:\<PID\> initialized successfullyIf a message like this appears, you did not set the environment variable properly
Release versions may not depend upon snapshots.
Freeze snapshots to dated versions or set the
LEIN_SNAPSHOTS_IN_RELEASE environment variable to override.Congratulations, you now have clojure-lsp working in OpenBSD!
If this doesn't happen and you have failures, or you see it sitting in the "starting" state for a long time, check the /tmp/lsp.out file to see what the error is.
When the driver is in place, once the nrepl server starts, it notices the DB was not present in the file system. Note, the only time that this particular warning was logged was when the system was able to load the OpenBSD version of the sqlite-jdbc driver.
INFO clojure-lsp.main: :initialize 55577 ()
INFO clojure-lsp.main: Shutting down
INFO clojure-lsp.main: Server started
INFO clojure-lsp.main: ====== LSP nrepl server started on port 32021
WARN clojure-lsp.main: Initialize
WARN clojure-lsp.db: Could not load db [SQLITE_ERROR] SQL error or
missing database (no such table: project)Enjoy your new installation!
Until the next blog, don't talk about it...
OS Upgrades can be Annoying
How many times have you wanted to upgrade the OS but found that it's not going to be as simple as you wanted or thought? This is especially true when you are going to a major version upgrade, but sometimes can even impact you on minor version upgrades.
If you haven't seen this occur, take a look at trying to upgrade a CentOS or RHEL6 system to version 7.X. You will very quickly see something relating to "recommended upgrade procedure is to reinstall from scratch". There is very little that I find more annoying than that. Why can't an OS simply upgrade, when it doesn't require a change if file system or similar? Also, on most systems, once you do upgrade the is a lot of dust left laying around that is no longer used by the system. My only response to this stuff is that the developers are too lazy to come up with a system that actually handles this for you. If you are someone who like me is frustrated at this, take a look at OpenBSD.
Sysupgrade makes it Simple
Below is an upgrade of one of my OpenBSD systems that I copied the process right from the terminal to show how simple it can be when the developers care about making it simpler. OpenBSD has always been pretty simple, in the past a version upgrade was performed using a boot USB stick, but now its even simpler.
Log into the system as root, and execute "sysupgrade -r"
milliways$ doas sysupgrade -r
SHA256.sig 100% |*****************| 2141 00:00
Signature Verified
INSTALL.amd64 100% |************************| 43550 00:00
base66.tgz 100% |*************************| 236 MB 00:22
bsd 100% |*************************| 18250 KB 00:05
bsd.mp 100% |*************************| 18336 KB 00:05
bsd.rd 100% |*************************| 10058 KB 00:04
comp66.tgz 100% |*************************| 72109 KB 00:11
game66.tgz 100% |*************************| 2745 KB 00:02
man66.tgz 100% |*************************| 7418 KB 00:03
xbase66.tgz 100% |*************************| 22092 KB 00:06
xfont66.tgz 100% |*************************| 39342 KB 00:08
xserv66.tgz 100% |*************************| 15757 KB 00:05
xshare66.tgz 100% |*************************| 4482 KB 00:02
Verifying sets.
Fetching updated firmware.
Upgrading.
Connection to milliways.wilcis.com closed.The system reboots automatically, and then it installs any firmware upgrades necessary. Once it comes back up, simply run the syspatch command which will apply any security or enhancement changes to the new version
Log into the system and run syspatch:
milliways$ doas syspatch
doas (roger@milliways.wilcis.com) password:
Get/Verify syspatch66-001_bpf.tgz 100% |****| 102 KB 00:00
Installing patch 001_bpf
Get/Verify syspatch66-002_ber.tgz 100% |****| 660 KB 00:00
Installing patch 002_ber
Get/Verify syspatch66-003_bgpd.tgz 100% |***| 181 KB 00:00
Installing patch 003_bgpd
Get/Verify syspatch66-004_net8021... 100% |*| 64839 00:00
Installing patch 004_net80211
Get/Verify syspatch66-005_sysupgr... 100% |*| 3023 00:00
Installing patch 005_sysupgrade
Get/Verify syspatch66-006_ifioctl... 100% |*| 381 KB 00:00
Installing patch 006_ifioctl
Get/Verify syspatch66-007_inteldr... 100% |*| 21468 KB 00:06
Installing patch 007_inteldrm
Get/Verify syspatch66-008_mesa.tgz 100% |***| 5598 KB 00:04
Installing patch 008_mesa
Relinking to create unique kernel... done;
reboot to load the new kernel
Errata can be reviewed under /var/syspatchWhat about Dust?
Dust is always a problem in every OS I've seen. Dust being old files that are no longer used by the OS post upgrade, but are not removed as part of the upgrade. Most OS's don't even mention it, because.. well space is cheap apparently. They could be an attack vector though if someone had access to a box. OpenBSD also handles this by listing all of the old files that can be manually removed. Every release comes with a page of upgrading instructions that include a section called "Files to Remove". Simply go there, copy the sections and paste them into a terminal... done.
Normally after removing the cruft, I upgrade the installed packages using
$ doas pkg_add -uivBoom Done ....
Reboot and you now have an upgraded system to the latest version... to coin Staples.... That was easy!
Until the next blog, don't talk about it...
Some History
I keep thinking about all of the killer applications and programming languages that have come along in recent years and the impacts that they made to the industry. Its also interesting to note how some of them fall off the radar over time that were once really popular. Ruby being the one that comes to mind in recent years. I suspect it really wasn't as great of a language but was instead propped up by an application, in this case Rails that used it. Having used Ruby for a number of years, I would say that I definitely have a preference for Python over Ruby and we now see Python moving into the DevOps world and becoming popular all over again there. That is in spite of the Python2 verses Python3 issues that keep raising their head. So Python went the way of Django and Ruby went the way of Rails, I could argue that Rails was more popular that Python for a number of years but now that has reversed. Anyone who has tried to update Rails or a number of Gems probably knows one of the major reasons why I believe Python is simply a better language to work with. Gems tend to be a nightmare, not when you first install them, but when you try to upgrade them down the road. So much so that people tended to not upgrade their Rails instances and before you know it, the version is no longer supported. I've seen in multiple times.
But what does this have to do with Clojurescript?
Think about how pervasive JavaScript has become to web development since it began back in the 90's. Currently it is pretty much impossible to have a web application that doesn't have some significant amount of JavaScript (JS) running asynchronous calls back to a web server that is probably leveraging REST to serve the queried information back to the client. That should give you some idea of how critical JS is to modern applications. Meanwhile there have been books written that have talked about how quickly JS was created, some stating as little as ten days. Not much time to get things right.
Anyone who has worked in JS for some time that isn't a full time JS developer, I put myself in that category, is likely to state that JS can be frustrating to work with and that errors seem to appear out of nowhere due to the syntax or just general semantics of the language.
So we have two things happening, an explosion of the language use coupled with a somewhat cantankerous language that is prone to errors. This is a recipe for exploits. So much so that in watching a YouTube video of Def-Con a few years ago they consider JS exploits basically like the kiddie pool for hackers. Definitely something that doesn't seem like we want to advocate using, but here we are and we are living with it daily. This doesn't mean JS is bad when programmed correctly, it simply means that programming it correctly can be tricky and is probably best left to dedicated front end developers for anything other than trivial use cases.
So what you would say to having a language that would let you compile your code behind the scenes into JS, but allow you to write something that looks exactly like Clojure to the point of many times being able to be shared by Clojure? In addition, when its compiled, it can be minimized for you automatically and even ran through the Google Closure compiler and optimized for performance. In addition to that, you can even "plug into" a running instance, update the code you program in, and the editor can then compile and restart the web instance updating the JS on the fly. Sound too good to be true, well its been available for a few years now, and its called Clojurescript.
In a future post, I will dig more into Clojurescript now that you have hopefully gotten a small taste of what it can do and are at least intrigued into digging into it a bit further.
Until the next blog, don't talk about it...
Something that I have been recently thinking a lot about is how bad
software appears to be in recent times. You can't seem to go through a day
without running into something that doesn't work as you would expect or
worse, just not work at all. If you start to search the web you will
see others that others have also started thinking about this same
phenomena in recent years. I've watched a handful of YouTube videos
in the past few weeks, that are all eluding the same thing. If you search
for them, I'm sure you will find many. An example of one that I recently
watched is from
Jonathan Blow.
His premise is basically that we have lost the understanding of the roots
of development due to abstractions, and that this is something that
has occurred over time for millennia with different domains, such as during
the bronze age. Its an interesting talk and I see where he is coming
from and I think he has some points that are valid, but he does come off
as a bit of an alarmist, at least to me.
So as time permits, and I really have no schedule, I wanted to push out some posts on this topic. What I think is happening (again just my own opinions) and what I think are ways forward. I don't believe this is an Kobayshi Maru scenario that Jonathan seems to think, but it is a problem, one that is solvable.
Until the next blog, don't talk about it...
Just got my Atom and RSS feeds enabled and configured. If you
want to subscribe to the feed, its relatively simple. Install a
plugin for your browser that allows subscribing to Atom feeds. Simply
look for the "Feeds" pulldown menu item in the navigation bar on the
top of the web page and select your preference. That will take you to
the respective xml file if you would like to look at its contents. I
personally am using the FeedBro client which once you have installed
and have the XML displayed in your window, select "Find Feeds in
Current Tab" and press "Subscribe" That is all there is to it.
The modifications in the source code to generate the XML feed were very simple and took about 5 minutes. I spent more time reading through the document and reading the code prior than I did actually writing it.
Until the next blog, don't talk about it...
Python is sooo baller. Been trying to get this Haskell app to fire up a web
server locally for my dev instance and I’m thinking forking, rebuilding,
yada yada yada. I wonder if there is some pythonic way to do this so I don’t
have to configure httpd or jump through so many hoops and sure enough...bam,
one liner. Kick it off in Emacs and it logs to stdout as a bonus.
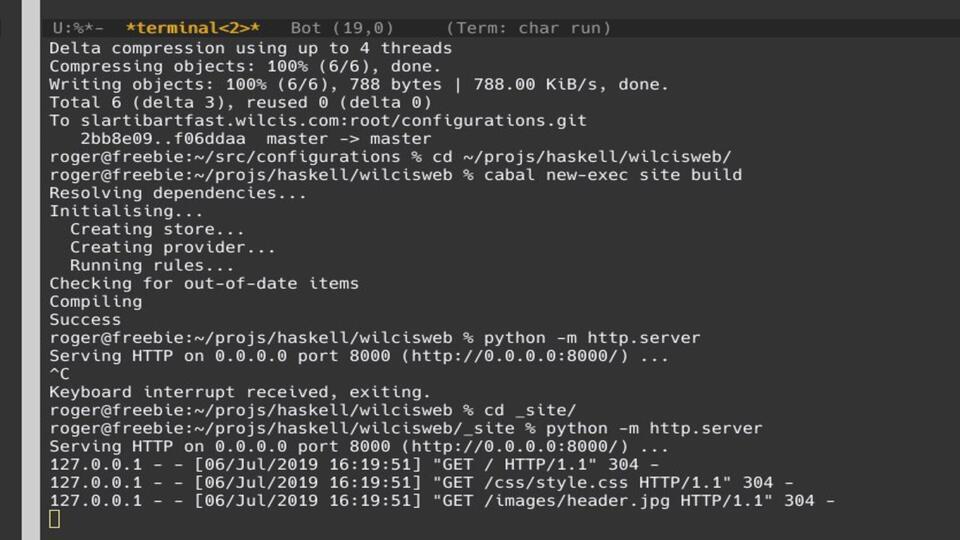
This is a huge time saver and for a development system is all that is required to have a good experience coding/compiling/viewing all within the confines of the Emacs editor. No need to switch screens to a terminal just to restart the web server as needed.
Until the next blog, don't talk about it...
Unless otherwise credited all material © Wilcis.com by Roger Williams